


Pipelining is a fundamental technique in modern computer architecture that significantly boosts processor performance by allowing multiple instructions to be processed concurrently. Rather than executing one instruction at a time in a sequential manner, pipelining divides the execution process into discrete stages, enabling different instructions to occupy different stages simultaneously. This overlapping approach transforms the CPU into a highly efficient assembly line, where each stage performs a specific function and continuously feeds the next stage with new instructions.
A typical pipeline includes five key stages: Fetch, Decode, Execute, Memory Access, and Write Back. The Fetch stage retrieves the next instruction from memory, Decode interprets it and identifies the necessary operands, Execute performs the required computations, Memory Access handles any data reads or writes, and Write Back records the results in the destination register. By structuring instruction execution this way, the CPU can initiate a new instruction in every clock cycle once the pipeline is full, dramatically improving throughput and resource utilization.
This concept is often compared to an industrial assembly line. Just as multiple products move through different stations simultaneously, instructions progress through their respective pipeline stages without waiting for previous instructions to complete all stages. The result is a substantial performance gain, allowing modern CPUs to handle complex workloads more efficiently, even in the face of challenges such as hazards and latency.
Key performance benefits of pipelining
Pipelining offers several critical advantages that make modern processors faster and more efficient. By overlapping instruction execution, it allows CPUs to achieve higher throughput, make better use of hardware resources, and reduce average cycles per instruction.
Increased instruction throughput
One of the primary benefits of pipelining is the significant increase in instruction throughput, which measures how many instructions a processor can complete per unit of time. In theory, a processor with k pipeline stages can achieve up to k times the speed of a non-pipelined processor running at the same clock frequency. For instance, a five-stage pipeline could process instructions nearly five times faster under ideal conditions. In real-world scenarios, performance gains typically range between 2.5× and 4× due to occasional stalls and hazards.

\(\text{Speedup} = \frac{\text{Throughput of pipelined processor}}{\text{Throughput of non-pipelined processor}} \approx k\)
Better resource utilization
Pipelining also maximizes the use of a processor’s functional units. In non-pipelined processors, certain components remain idle while waiting for others to finish, leading to wasted cycles. Pipelining ensures that while one instruction is being decoded, another can execute, and yet another can access memory. This overlap minimizes idle hardware and allows the CPU to operate at higher efficiency.
Reduced average latency
Although pipelining does not reduce the time it takes for an individual instruction to complete, it lowers the average cycles per instruction (CPI) by executing multiple instructions concurrently. By completing more instructions per clock cycle, overall system performance improves even if single-instruction latency slightly increases due to pipeline overhead.
Together, these benefits explain why pipelining is a cornerstone of high-performance processor design, forming the foundation for modern CPU efficiency and speed.
Detailed pipeline stages
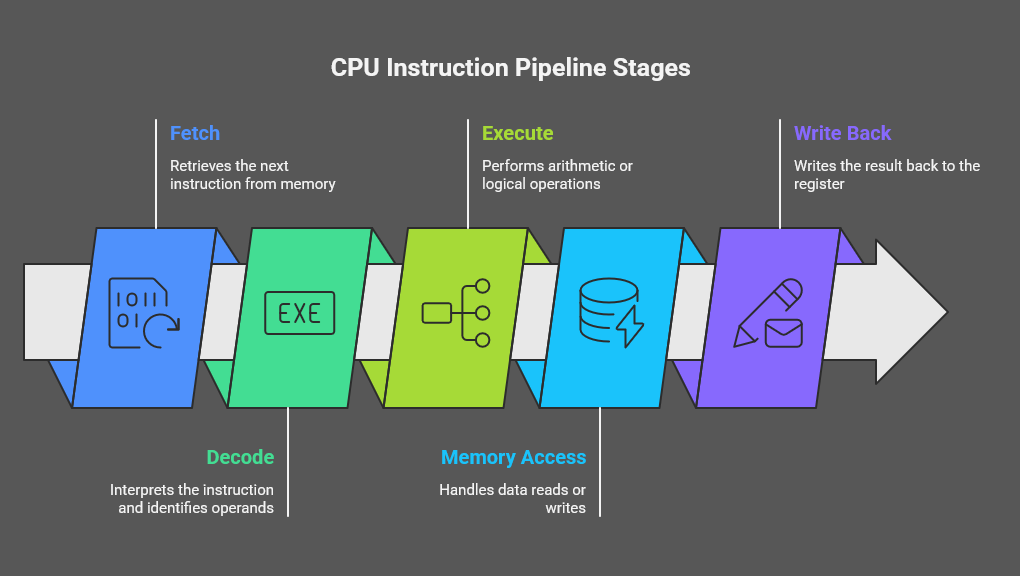
A classic CPU pipeline typically consists of five main stages, each responsible for a distinct part of instruction execution. Understanding these stages is essential to appreciating how pipelining improves performance.

| Stage | Function |
| Fetch (IF) | Retrieves the next instruction from memory using the program counter (PC). This ensures the CPU always has an instruction ready for decoding. |
| Decode (ID) | Interprets the fetched instruction, identifies the required operands, and reads values from the registers. |
| Execute (EX) | Performs arithmetic or logical operations using the ALU (Arithmetic Logic Unit). |
| Memory Access (MEM) | Handles any data reads or writes, allowing instructions that require memory interaction to complete their operations. |
| Write Back (WB) | Writes the final result of the instruction back to the destination register, completing the instruction’s journey. |
Beyond these core stages, modern processors often include additional mechanisms to handle more complex instructions and improve performance. These include branch prediction, which anticipates the direction of program branches to reduce pipeline stalls; register renaming, which avoids conflicts between instructions using the same registers; and micro-op translation, which breaks down complex instructions into simpler micro-operations for faster execution.
By dividing instruction execution into these stages, pipelining allows the CPU to process multiple instructions simultaneously, much like an assembly line where different workers handle separate tasks on multiple products at the same time. This structure is fundamental to the performance gains observed in modern processors.
Each instruction in the pipeline is represented in the binary number system, which is the native language of CPUs. This allows the processor to perform arithmetic, logical, and memory operations efficiently at the hardware level.
Challenges and pipeline hazards
While pipelining significantly improves processor performance, it also introduces challenges that can reduce efficiency if not properly managed. These challenges are commonly referred to as pipeline hazards and fall into three main categories.
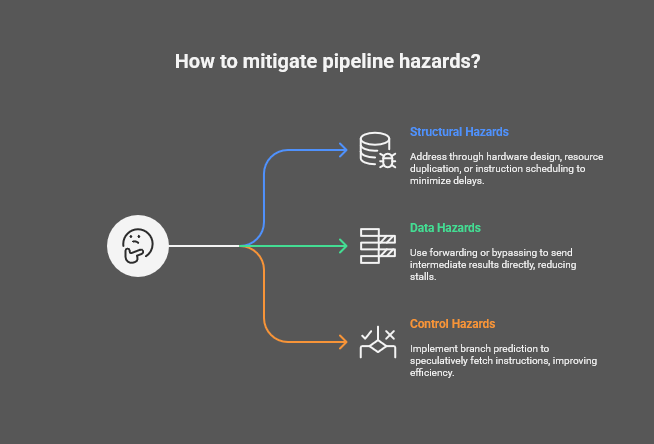
Structural hazards
Structural hazards occur when multiple instructions compete for the same hardware resources, such as the ALU or memory. This conflict can force the pipeline to stall until the resource becomes available. Modern architectures address structural hazards through careful hardware design, resource duplication, or instruction scheduling to minimize delays.

Data hazards
Data hazards arise when an instruction depends on the result of a previous instruction that has not yet completed. For example, a Read-After-Write (RAW) hazard occurs when an instruction tries to read a value before the preceding instruction writes it. Techniques like forwarding or bypassing allow intermediate results to be sent directly to later stages, reducing the need for stalls and keeping the pipeline flowing.
Control hazards
Control hazards occur when branch instructions alter the program counter, disrupting the flow of subsequent instructions. To mitigate these hazards, processors use branch prediction, which speculatively fetches instructions based on predicted outcomes. Although mispredictions require flushing the pipeline and re-fetching instructions, branch prediction significantly improves overall efficiency.
Despite these challenges, careful architectural strategies and advanced techniques ensure that pipelines remain highly effective. Understanding these hazards is crucial for designing CPUs that balance complexity with maximum performance.
The enduring significance of pipelining
Pipelining has proven to be a cornerstone of modern computer architecture, enabling processors to achieve remarkable performance improvements through concurrent instruction execution. While challenges like structural, data, and control hazards can limit theoretical gains, techniques such as forwarding, branch prediction, and out-of-order execution help maintain high efficiency.
The evolution of pipelining, from early implementations like the MIPS R2000 five-stage pipeline to deeply pipelined designs in processors like the Intel Pentium 4, demonstrates its critical role in supporting higher clock frequencies, increased throughput, and more complex computing tasks. Modern processors, with pipelines ranging from 10 to 20 stages, power applications that demand billions of operations per second, from advanced 3D rendering to big data analytics.

As processor designs continue to evolve with multi-core and heterogeneous architectures, pipelining remains essential for maximizing performance and resource utilization. Understanding pipelining provides insight into how modern CPUs handle vast workloads efficiently and why this technique continues to shape the future of computing.










